Running microsimulations in Stata
Eduard Bukin
microsim-stata.RmdMicrosimulation is a software product that uses micro-level data and input parameters for simulating potential distributional effects of alternative policies. Basic examples of such policies are personal income taxes, indirect taxes, subsidies, and benefits in kind. Usually, economists develop microsimulations in Stata connected with Excel, where the first is used to execute data analysis and the later one is used for providing policy inputs and visualizing the results. Example_FiscalSim is an example of such a microsimulation analysis.
Most microsimulation analyses are developed in Stata. They have a predetermined structure that makes such Stata-based tools efficient, transparent, and reproducible. Usually, such Stata tools consist of:
Raw data. It consists of household or individual-level micro surveys with multiple data files that store different bits of information, e.g. consumption records by goods or groups of commodities for each household or individual, income levels by sources and individuals, and assets owned by households. This data is usually extremely detailed and only a fraction of it is used in the simulation analysis. This data is stored in different formats (CSV, excel, dta, etc.).
Pre-simulation analysis. This is Stata code that uses Raw data and produces pre-simulation data. Its goal is to reduce the diversity of Raw data sets of a very limited and restricted set of data files with only a handful of variables used in the simulation. It is executed only once and it is not re-executed when our policy parameters change. Only the pre-simulation data is used in the following simulation steps. Typical examples of such data that is computed at the pre-simulation stage are grossed-up incomes and policy eligibility criteria such as gender and age, or other local conditions on which certain taxes or subsidy policies are applied.
Note. Often, when we convert Net income/consumption levels (after taxation) into gross income/consumption, we apply policy parameters, which existed at the time of data collection. These parameters should be provided manually at the pre-simulation stage and they should never be confused with the simulation-related policy parameters.
Policy parameters. These are numerical values such as tax levels in % or subsidy levels in monetary value, which we simulate at the simulation step. These are usually provided in the Excel files and in the Stata code they are used as
globals.Simulation itself. This is a collection of
.dofiles that executes the simulation based on pre-simulation data and policy parameters. These are executed consecutively and gradually implement the simulation analysis.Results processing. A single data file with all variables and income concepts was simulated during the analysis. Based on it, we compute poverty and inequality measures as well as the distributional effect of policies.
Once the microsimulation is developed in Stata and it contains clearly defined all five components explained above, we can commence developing the microsimulation in R and subsequently the R Shiny application with the microsimulation dashboard.
Note. Usually, the first step is implemented in an ad-hoc way by economists, who are not aware of best coding practices and fundamental principles of data flow. Therefore, the first stage is rather chaotic. In the second stage, considerable revision of the data flow and simulation logic is happening. This two-stage approach is resource-demanding, but it also reveals many limitations and problems of the original analysis in Stata.
Example of a microsimulation in Stata
As an example, let us follow up with a “dummy” version of such a microsimulation: Example_FiscalSim. It was developed for the training of future microsim developers and it exemplifies the best practices of fiscal microsimulation development.
Setting up the working directory
-
Create a folder on your cloud drive (or better a not synchronized drive), where you will later develop R Shiny translation of the microsimulation.
In my case, this is folder
EPL/devCEQaux. -
Clone into this folder example microsimulation in Stata from:
-
Open the
Example_FiscalSimfolder and explore its content.As you can see from the directory tree below,
Example_FiscalSimcontains a few folders./01.Data/folder in turn has three sub folders/01.pre-simulation/,/02.intermediate/, and/03.simulation-results/and two data files with raw dataExample_FiscalSim_dem_inc_data_raw.dta, andExample_FiscalSim_exp_data_raw.dta. Ultimately, the raw data should be outside of this project, but we packed it together for simplicity./01.Data/01.pre-simulation/is the place where pre-simulation data is stored as per the data flow structure above./02.Dofile/is the place where all simulation code is being developed. Key simulation code is in scripts01_.._.doto12_output.do./02.Dofile/00_master.dois the master script from which we will be running the simulation./03.Tool/Example_FiscalSim.xlsxis the Excel file with all simulation inputs (policy parameters, tax rates, and subsidies) and outputs (poverty and inequality estimates, incidences, etc.).
./devCEQaux/
└── Example_FiscalSim
├── 01.Data
│ ├── 01.pre-simulation
│ ├── 02.intermediate
│ ├── 03.simulation-results
│ ├── Example_FiscalSim_dem_inc_data_raw.dta
│ └── Example_FiscalSim_exp_data_raw.dta
├── 02.Dofile
│ ├── 00_master.do
│ ├── 01_input_data.do
│ ├── 02_gross_market_income.do
│ ├── 03_net_expenditures.do
│ ├── 04_income_uprating.do
│ ├── 05_SSC_direct_taxes.do
│ ├── 06_pensions_direct_transfers.do
│ ├── 07_expenditure_adjustment.do
│ ├── 08_indirect_subsidies.do
│ ├── 09_indirect_taxes.do
│ ├── 10_inkind_transfers.do
│ ├── 11_income_concepts.do
│ ├── 12_output.do
│ ├── ados
│ │ ├── ...
│ └── Example_FiscalSim.stpr
├── 03.Tool
│ └── Example_FiscalSim.xlsx
└── README.mdRunning pre-simulation in Stata
To run the Stata pre-simulation, we need to:
Open
/02.Dofile/00_master.do.Set the global variable
pathin lines 10-30 to/Example_FiscalSim/and save it.-
Execute the
/02.Dofile/00_master.dofrom the beginning to the*Simulation stage(Lines 1-89).This will execute the pre-simulation part of your analysis creating the pre-simulation data sets (see folder structure below).
You may notice that now, more data files are added to the
01.Data/01.pre-simulationfolder. These files are used in the simulation and they do not change from simulation to simulation. They do not change if policy parameters are changing. They will also serve as a backbone of the simulation translation to R.If an error is prompted, troubleshoot it. Most likely the global variable
pathwas not set properly.
./devCEQaux/
└── Example_FiscalSim
├── 01.Data
│ ├── 01.pre-simulation
│ │ ├── Example_FiscalSim_dem_data_SY.dta
│ │ ├── Example_FiscalSim_dem_inc_data.dta
│ │ ├── Example_FiscalSim_electr_data.dta
│ │ ├── Example_FiscalSim_exp_data_SY.dta
│ │ └── Example_FiscalSim_market_income_data_SY.dta
│ ├── 02.intermediate
│ ├── 03.simulation-results
│ ├── Example_FiscalSim_dem_inc_data_raw.dta
│ └── Example_FiscalSim_exp_data_raw.dta
├── 02.Dofile
│ ├── ...
│ └── ados
│ ├── ...
├── 03.Tool
│ └── Example_FiscalSim.xlsx
└── README.mdExecuting full simulation in Stata
To run the full simulation in Stata, we need to:
Open
/02.Dofile/00_master.dowith previous changes and make sure that the pre-simulation step was executed correctly.Comment out the pre-simulation stage (lines 83-89).
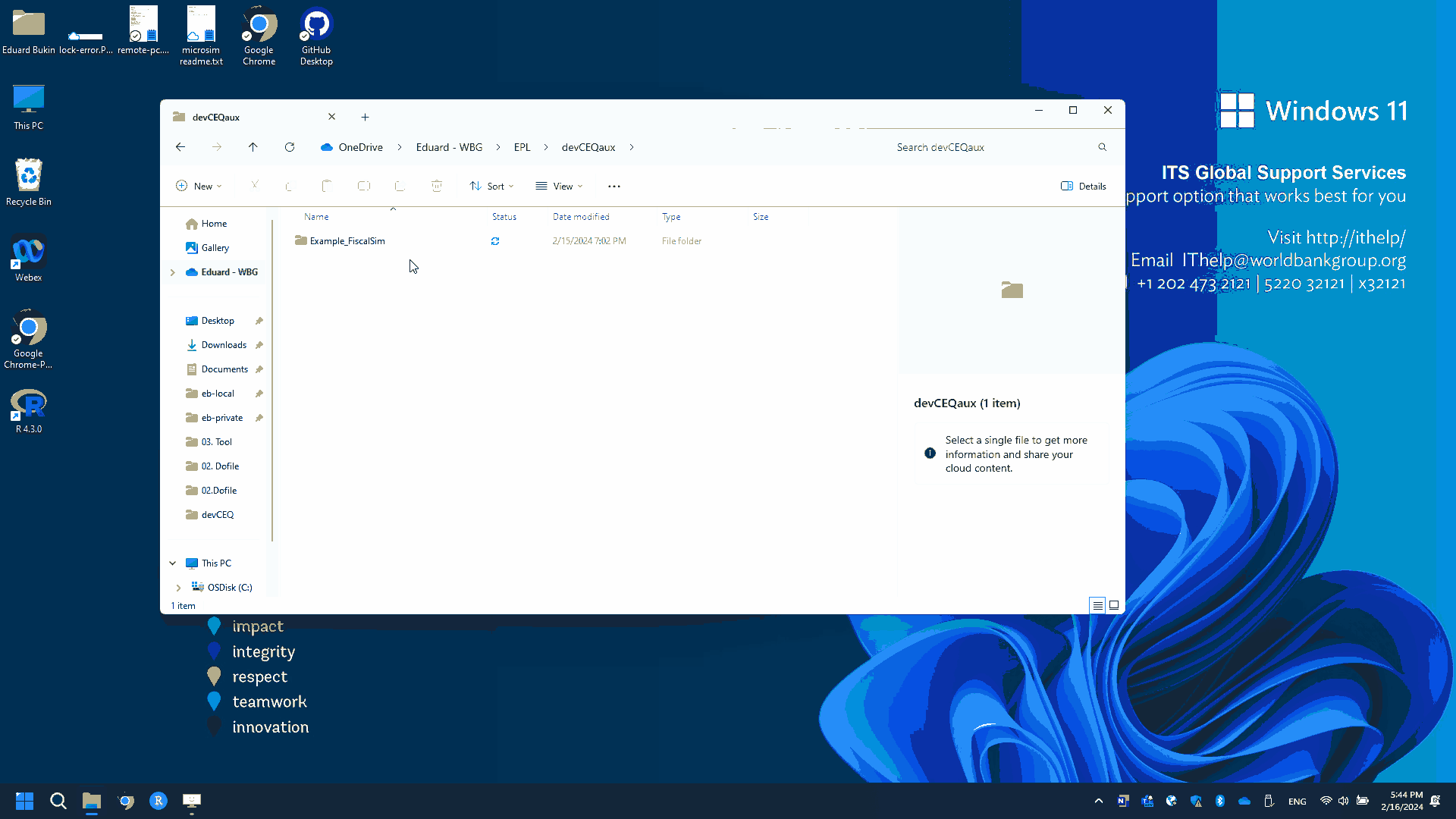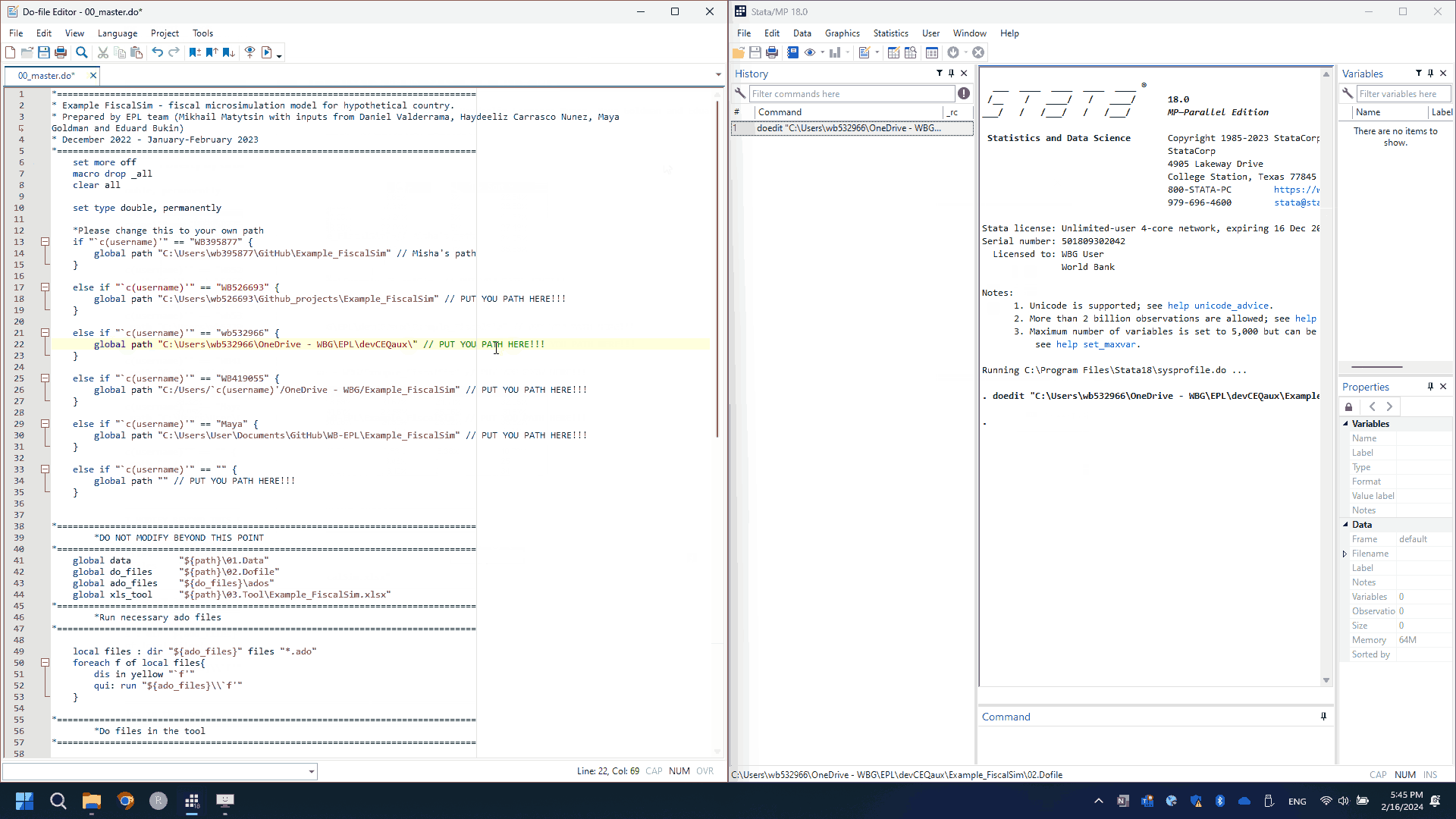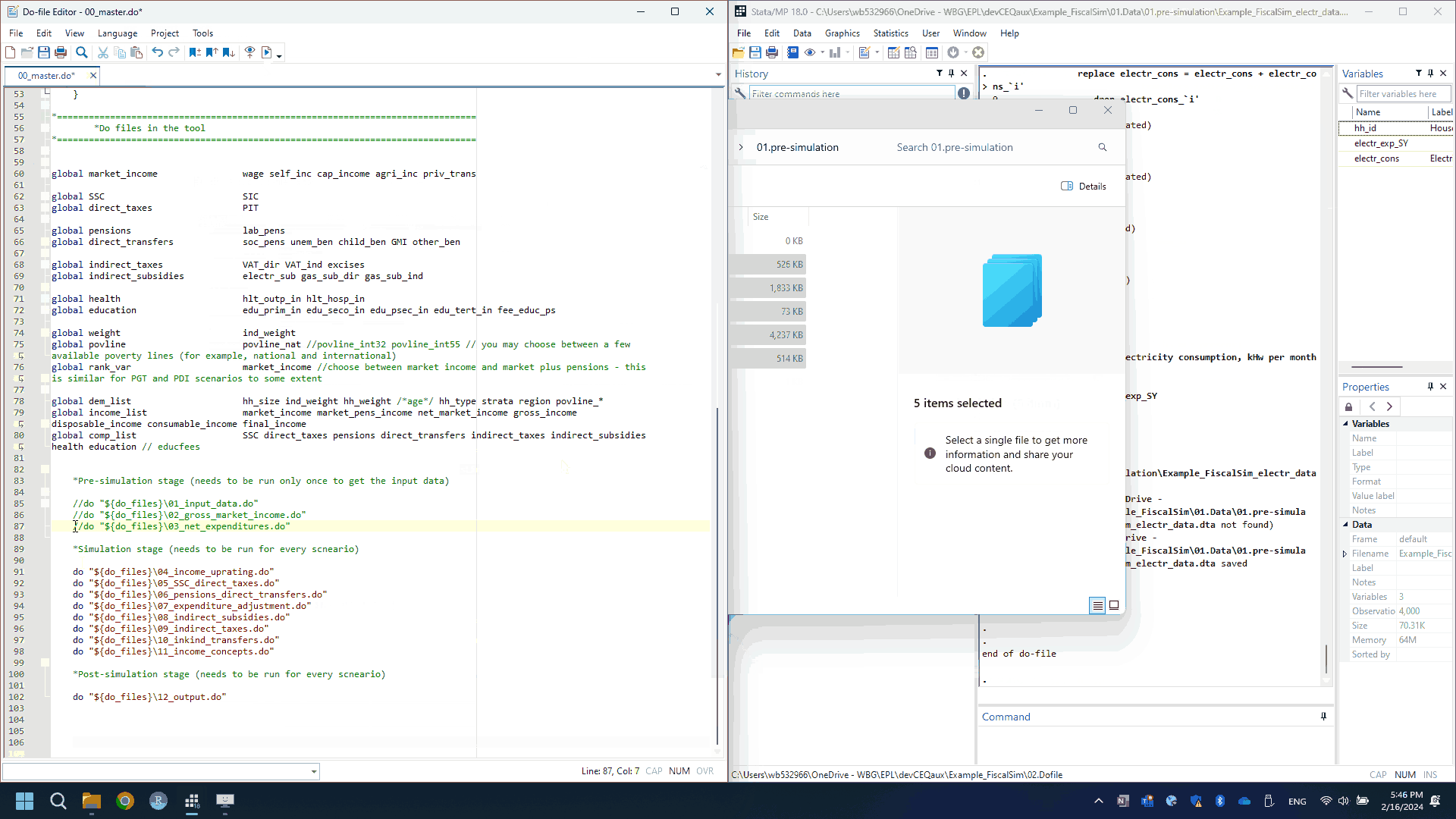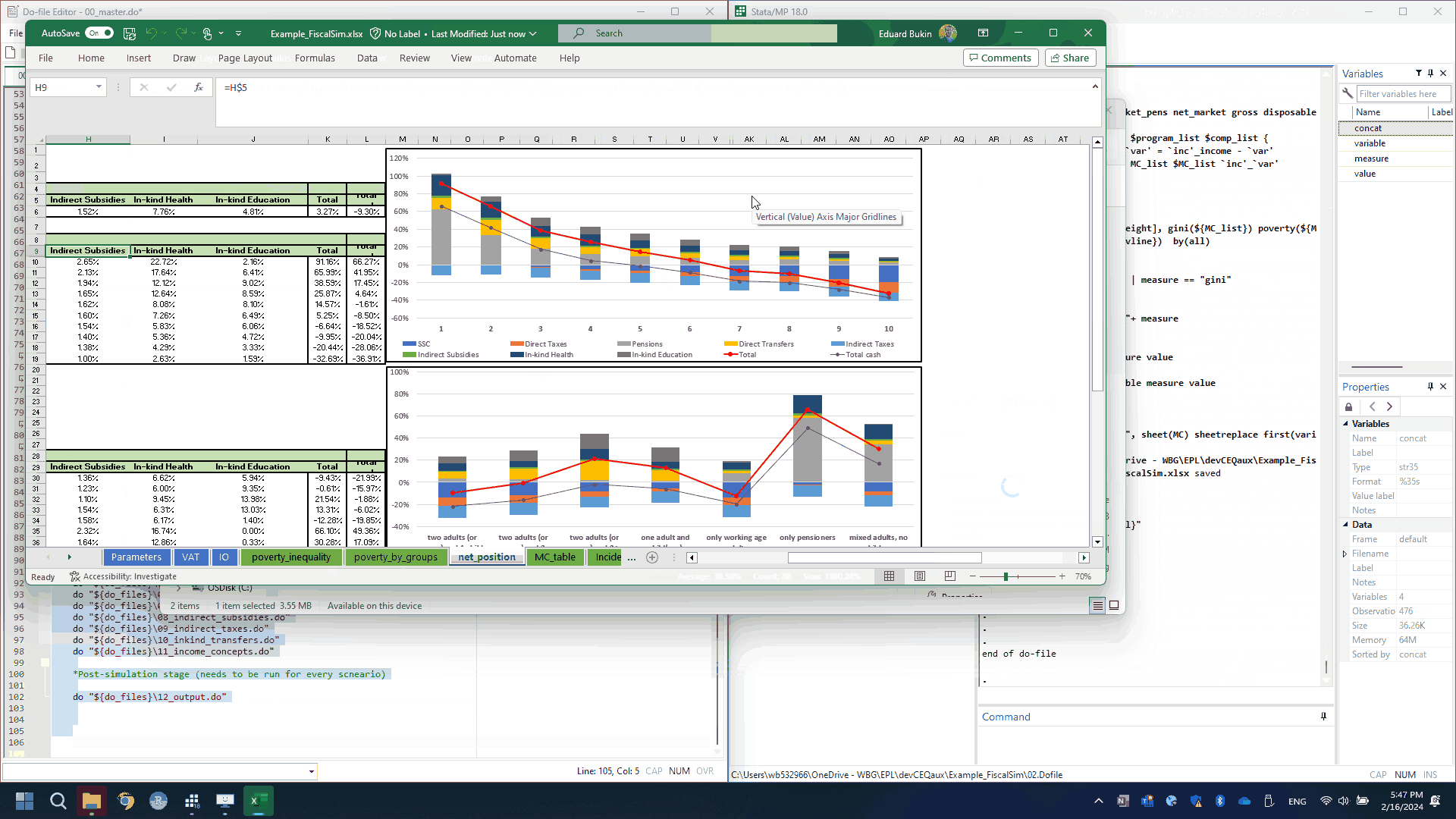
Execute the full simulation from the beginning to the end (line 1 to the end of the
00_master.do)An Excel file with the simulation results will open in the end and you will be able to explore the simulation results.
Saving intermediate results from Stata
Sometimes, when simulations are very long, or we are implementing a
tedious process of simulation translation, and re-implementing some
complex analysis in R, we might need to save intermediate data sets from
Stata. Please make sure that you are saving such data in the
/01.Data/02.intermediate/ folder using regular Stata
commands such as: